PDF 편집 도구를 직접 가상서버에 호스팅하는 방법을 알아보겠습니다.
물론 내 컴퓨터 로컬에서 동작할 수 있는 Split PDF(확장 프로그램) 또는 PDF Arranger(윈도우 프로그램) 등도 있고 iLovePDF와 같은 사이트도 있지만 로컬에서 작동하는 프로그램은 대개 간단한 기능(합치기, 분할)만 있고 사이트 같은 경우 용량 제한이 걸려져 있습니다.
iLovePDF도 UI가 깔끔해서 자주 사용하지만 무료로 사용하는 경우 100MB 제한이 걸려져 있는 걸 확인할 수 있습니다. 이 글은 용량 제한 없이 PDF 파일을 편집하고 싶을 경우 가상서버에 직접 프로그램을 호스팅하는 방법을 설명합니다.
깃헙에 오픈소스로 공개된 Stirling PDF를 사용할 것이며 가상서버는 본인이 원하는 걸 사용하면 되지만 이 글에서는 오라클 프리티어를 이용하겠습니다.
오라클 프리티어에 관한 내용은 워드프레스 공략글을 쓰며 설명한 적 있으니 궁금한 경우 참고하면 됩니다.
이지패널 설치하기
먼저 가상패너에 도커 기반 웹 패널인 이지패널을 설치하도록 하겠습니다. 이지패널 같은 웹 패널을 이용하면 SSH에서 명령어를 입력하는 과정을 줄이고 간단하게 앱을 설치할 수 있습니다.
오라클 클라우드 이지패널(EasyPanel) 설치 및 업그레이드
이지패널을 설치하는 방법 또한 이미 설명한 적 있으므로 궁금하신 분은 참고하면 됩니다.
이지패널에 Stirling PDF 설치하기
설치 방법은 아주 간단합니다. 새로운 프로젝트를 만들고 오른쪽 위의 Service를 클릭합니다.
App을 선택합니다.
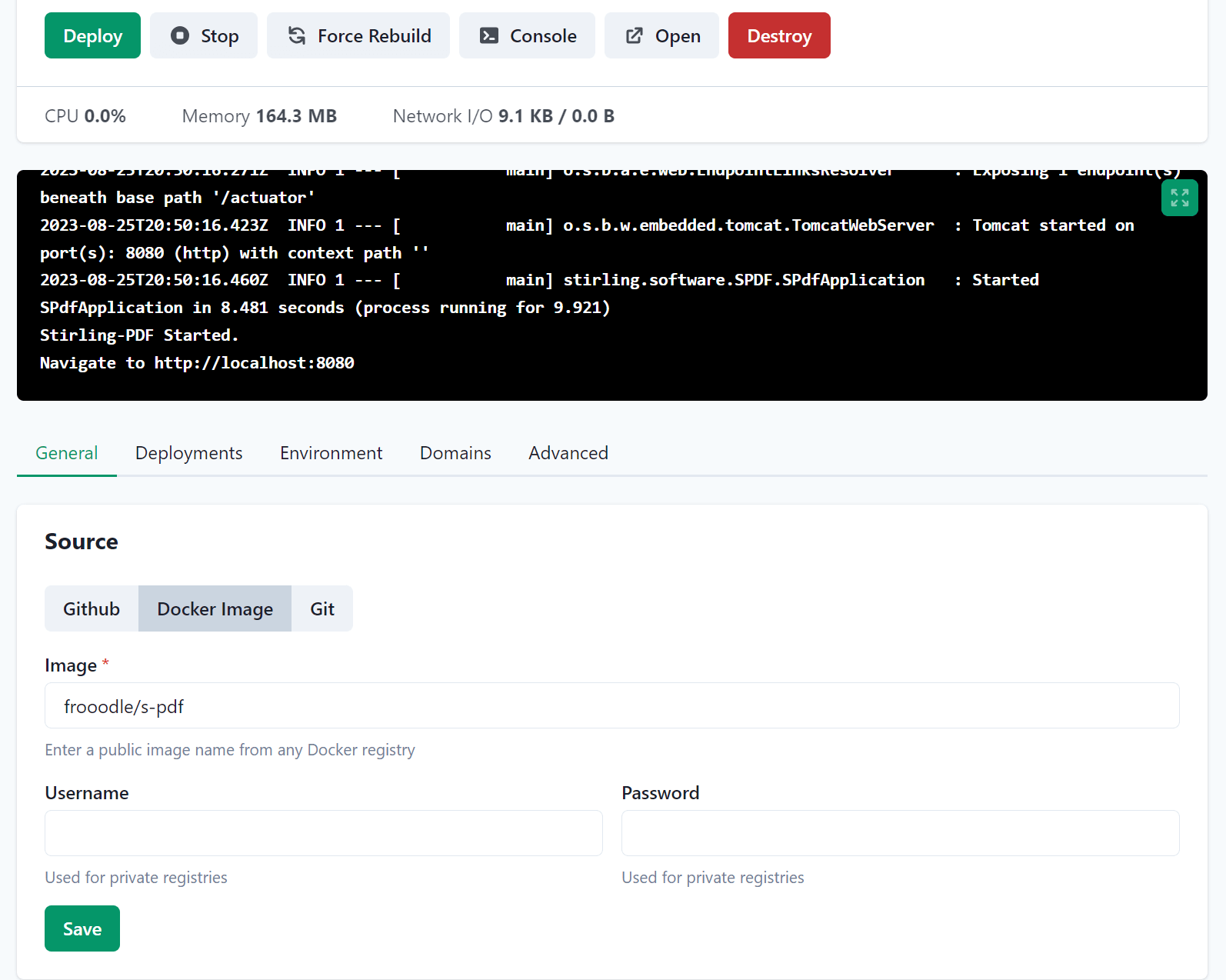
이제 General – Docker Image – Image에 frooodle/s-pdf를 입력하고 Save를 클릭한 뒤 위의 Deploy를 클릭합니다.
오픈소스로 공개되어 있는 코드를 활용합니다. 프로그래머가 이미 도커 이미지를 만들어놨기 때문에 해당 도커 이미지의 주소를 입력하면 자동으로 설치가 됩니다.
Deploy는 이지패널이 제공하는 일종의 새로고침 같은 기능입니다.
Open을 누르면 임의로 생성된 링크를 통해 Stirling PDF에 접속할 수 있습니다.
물론 이지패널을 이용해 본인이 구매한 도메인을 연결할 수도 있습니다. 그러나 혼자 사용하는 게 목적이라면 굳이 도메인을 설정할 필요는 없겠죠.
Stirling PDF의 단점? 여전히 개발중이다
Stirling PDF는 오픈소스로 여전히 개발되고 있는 프로젝트입니다. 때문에 시중에 있는 유료 PDF 편집 프로그램과 비교해서는 기능이 다소 부족한 게 사실입니다. 정확히 말하면 기능은 많은데 편리성이 부족합니다. PDF 페이지 추출 같은 경우 시중 프로그램은 미리보기를 보여주고 클릭을 해서 추출하는 방식인데 Stirling PDF는 본인이 기억하고 온 페이지 숫자를 입력해야 합니다.
PDF Multi Tool이라고 미리보기가 가능한 도구가 있긴 하나 한 번에 보여지는 페이지 수가 너무 적고 로딩이 느립니다. 게다가 PDF 업로드 및 다운로드 과정이 표시되지 않아 진행상황을 알 수 없습니다.
이러한 단점은 개발자가 열심히 수정하는 중입니다. 업데이트 된 버전이 깃헙에 올라오는 경우 나중에 다시 Deploy를 누르면 새로고침(업데이트)이 실행됩니다.
OCR 활성화
sudo apt install tesseract-ocrTesseract-OCR 설치
apt-get install tesseract-ocr-kor한국어 데이터 추가
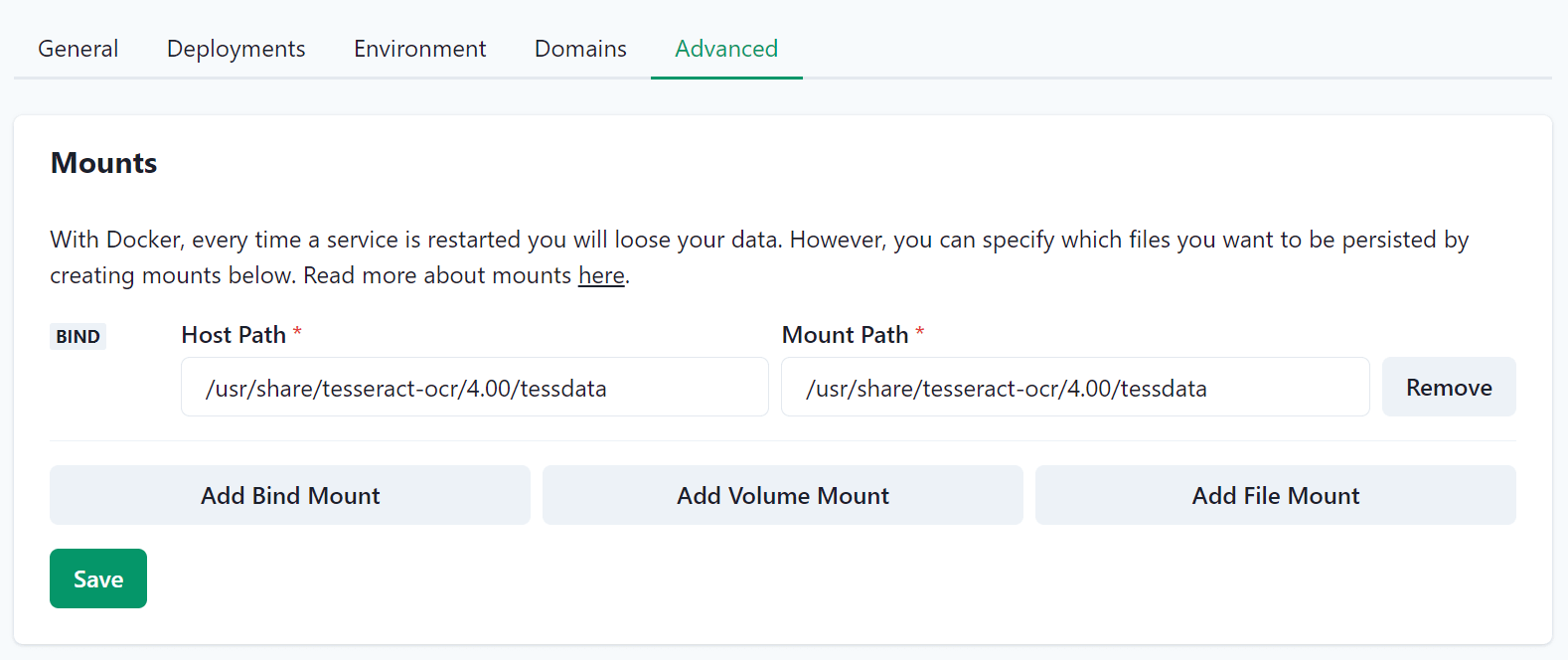
이지패널 Add Bind Mount 설정
Host Path : 방금 추가한 한국어 데이터가 저장된 경로입니다. 운영체제마다 조금씩 다를 수 있으나 우분투는 위 사진과 같습니다.
Mount Path : Stirling PDF에서 설정해놓은 경로로 위 사진과 같이 입력하면 됩니다.
Save 버튼을 클릭하고 Deploy 버튼을 클릭해서 재시작합니다.
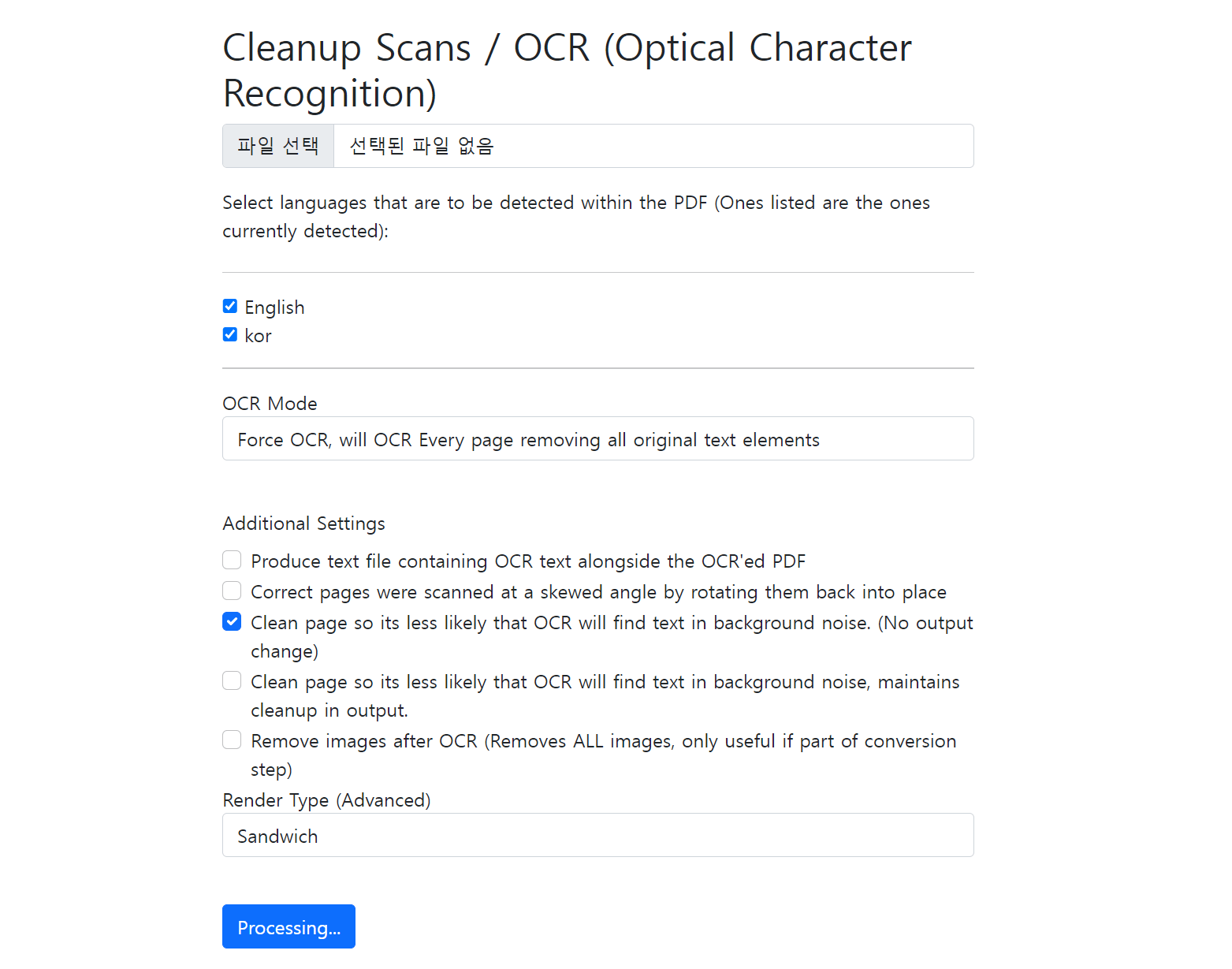
한국어가 추가된 모습입니다.
PDF에 여러 개의 언어가 사용되었다면 전부 선택해야 합니다. 예를 들어 영어와 한국어가 함께 사용된 PDF라면 English, Kor 두 가지 언어를 선택합니다.
OCR Mode – 텍스트가 있는 페이지를 건너뛸 지, 텍스트가 있는 페이지라도 OCR을 진행할 지 등을 선택합니다.
Render Type (Advanced) – HOCR, Sandwich 두 개가 있는데 HOCR는 영어만 인식할 수 있으니 한국어를 인식하려면 Sandwich를 사용해야 합니다.
마치며
직접 사용해본 결과 용량 제한 없이 PDF 합치기, 압축 등을 실행할 수 있다는 점이 가장 좋았습니다. 특히 PDF 압축의 경우 단계가 나눠져있는데 2단계 정도만 사용해도 화질 변화 없이 1/3 정도로 용량이 줄어드는 걸 확인했습니다.
PDF는 기본적으로 이미지 파일을 모아놓은 형태입니다. 때문에 압축과 같은 과정을 실행하기 위해서는 서버에 업로드 후 다운로드 하는 과정이 필요하고 이 과정에서 램, CPU, 트래픽 등 자원을 소모하게 되어 무료로 서비스를 제공하는 게 어렵고 그런 이유로 시중 프로그램에 대부분 페이월(PayWall)이 걸려있습니다.
본인의 서버를 사용해 PDF 프로그램을 구동하면 그런 제한을 걱정할 필요 없습니다.
그리고 이번에 새로 알게된 게 있는데 PDF를 인식해서 텍스트로 변환하는 OCR 기능이 CPU를 엄청나게 소비합니다. 4vCPU로 구동해도 100%를 계속 유지하는 걸 보면 어중간한 사양으로는 구동하기 힘들 것 같습니다.